到目前为止,简单的五级流水线CPU已经基本实现完毕。指令也基本都加上了,除了除法指令和Trap指令。
尝试在Synplify中尝试综合了一下,目前的流水线差不多可以跑到47.5MHz,如图:

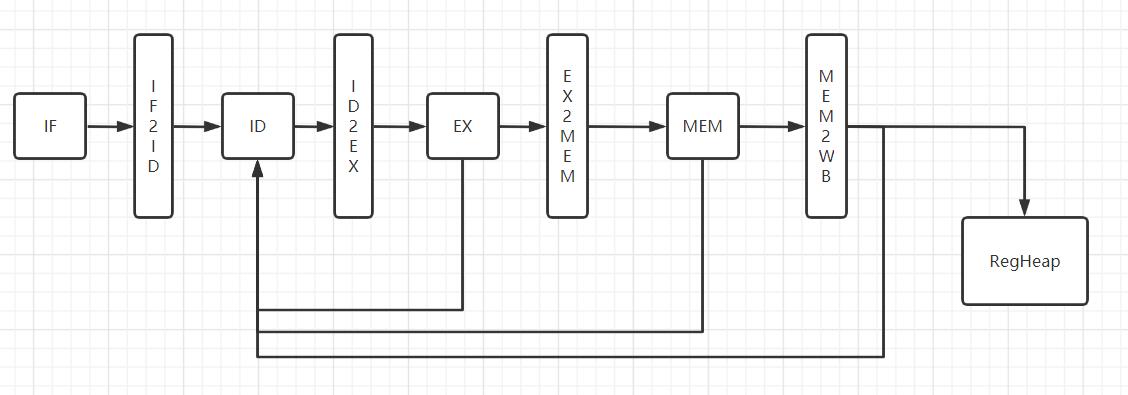
之前在解决数据冒险的时候说过,当时是直接将EX/MEM/WB的输出拉回ID来解决的数据冒险(参考《自己动手写CPU》),同时,也分析了这种
方法会增大ID模块的延迟,从而降低流水线的速度。因此,这次来好好优化一下这个数据冒险的问题。
去掉WB级
之前没有注意,最近仔细阅读了一下《计算机组成——软硬件接口》中的相关内容,发现在该书中关于流水线的描述与《自己动手写CPU》有点区别。
软硬件接口中的WB级,实际上是“虚构的”,MEM之后直接接入了寄存器组,因此一旦MEM输出完毕后,下一个周期寄存器组就可以写入内容。
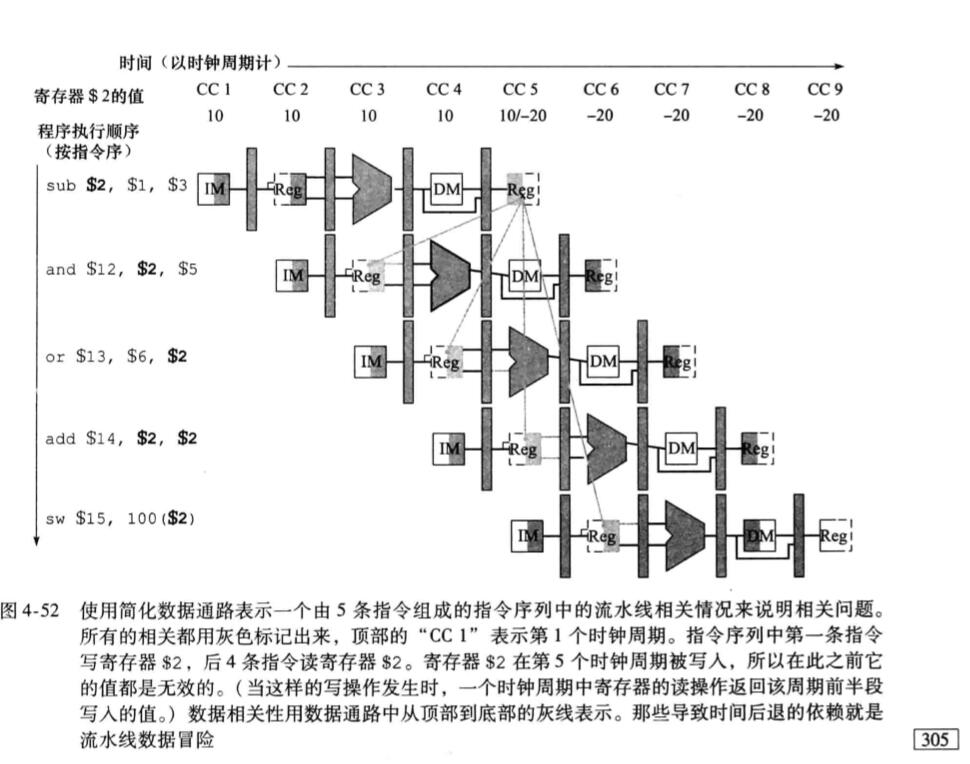
而在《自己动手写CPU》中,MEM之后还有一个MEM2WB的流水线暂存级,暂存级之后才连接的寄存器组,因此导致MEM输出完毕后,需要两个周期才能写入数据。
因此之前按照《自己动手写CPU》实现的流水线效果如图:(ID在第1个时钟沿,写入寄存器在第5个时钟沿,中间相差4个时钟)

当时解决数据冒险时候提到的一种情况么:
ORI $1 = $0 | 1100
NOP
NOP
ORI $2 = $1 | 0011这种情况,当指令2在译码时,指令1才刚到写回,此时写回阶段已经将写入地址和写入值放在了数据线上,但是要等下一个时钟寄存器组才会将值写入。
因此,如果将WB级去掉,或者说将其变为“虚构的”,这种情况是实际上就不需要考虑了。
去掉之后的流水线效果:(ID在第1个时钟沿,写入寄存器在第4个时钟沿,中间相差3个时钟)(与软硬件接口中的描述一致)

修改旁路
前面的去掉WB级实际上只是简化硬件,实际上并不能加速流水线,真正加速流水线需要修改之前的旁路实现。
修改旁路的的几点:
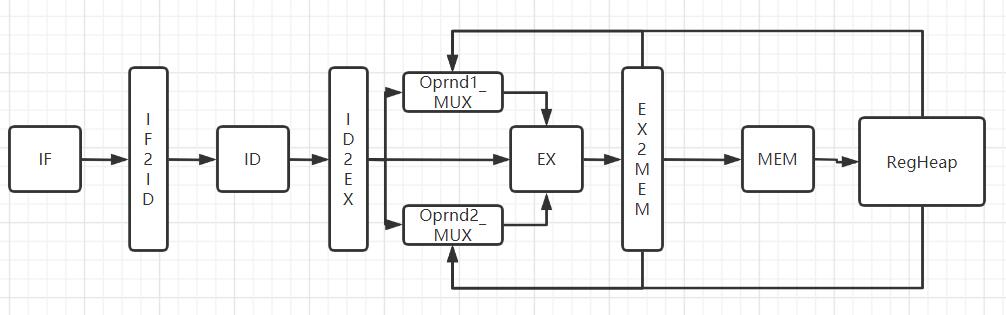
- 将旁路由EX、MEM、WB的组合逻辑返回,改为由EX2MEM\Reg的时序逻辑返回
- ID需要将当前指令是否读取寄存器、读取哪个寄存器 输出给ID2EXE
- EXE前面增加两个操作数的MUX,该MUX连接ID2EXE 以及 EX2MEM\Reg,用来判断当前使用的寄存器操作数,是否在上一条或者上两条指令中会被修改,如果会,就使用修改后的值
旧流水线示意图:
新流水线示意图:
流水线修改后,时钟约束之下,可跑到更高的频率了:
